Azure Machine Learning SDK v2 を使用し、以下の Azure Machine Learning パイプラインの利用例について紹介させていただきます。今回紹介するライフサイクルは次の通りです。
- 自動機械学習を実行
- ベスト モデルを選択して Managed Online Endpoint にデプロイ
今後、以下が実行できるよう更新予定です。
- 公開したパイプライン実行時に、データ アセットの最新バージョンを使用して AutoML が実行されるようにする
- パイプライン実行毎に既存のエンドポイントが更新されるようにする
イメージ
// ライフサイクルは以下のようなイメージです。これを参考に後述の手順をご確認ください。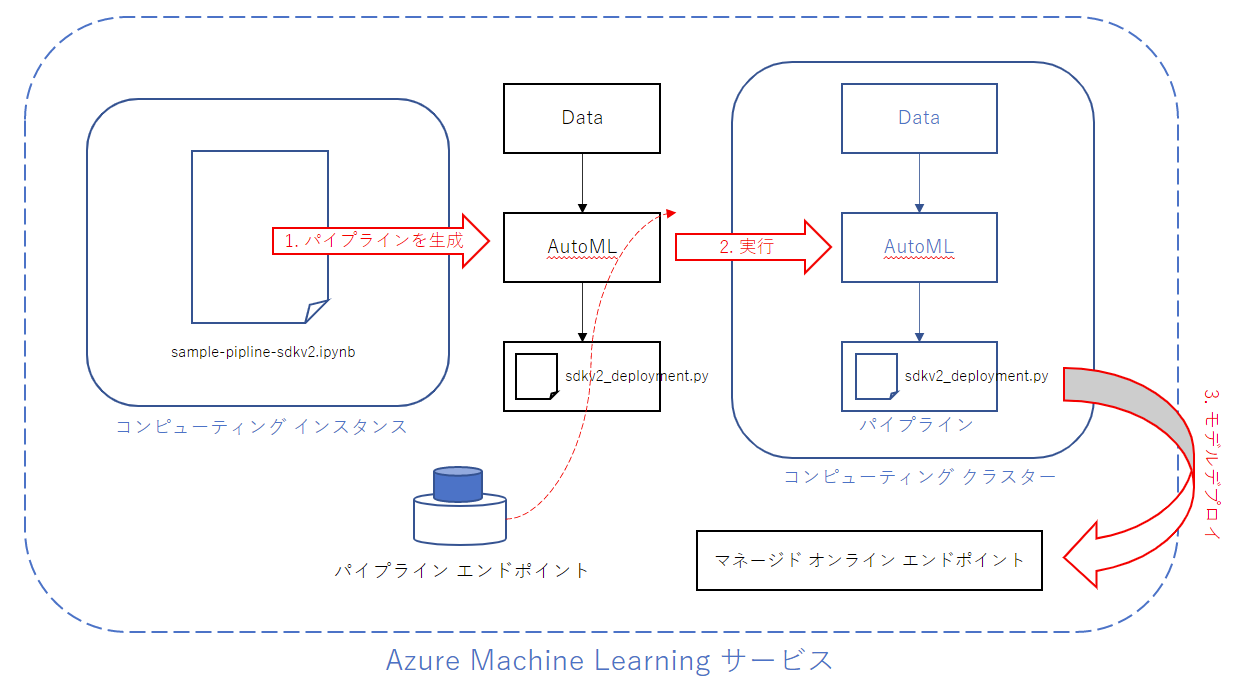
準備
以下リンクより sample-pipeline-sdkv2.zip ファイルをダウンロードし、ローカル上で解凍します。解凍後のフォルダーを、Azure Machine Learning Studio の Notebooks メニューのファイル ツリーのうち、任意の場所にアップロードします。
※ 保存されているファイル一覧
・ data フォルダー
├ MLTable ファイル
└ training-machine-dataset.csv ファイル
・ aml-pipeline-sample-sdkv2.ipynb ファイル
・ test.json ファイル
// フォルダーを配置した状態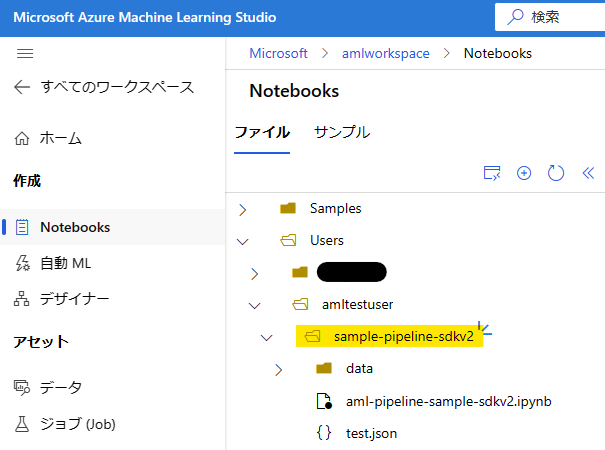
// 上記ファイルを使って以下のような処理を行うパイプラインを作成します。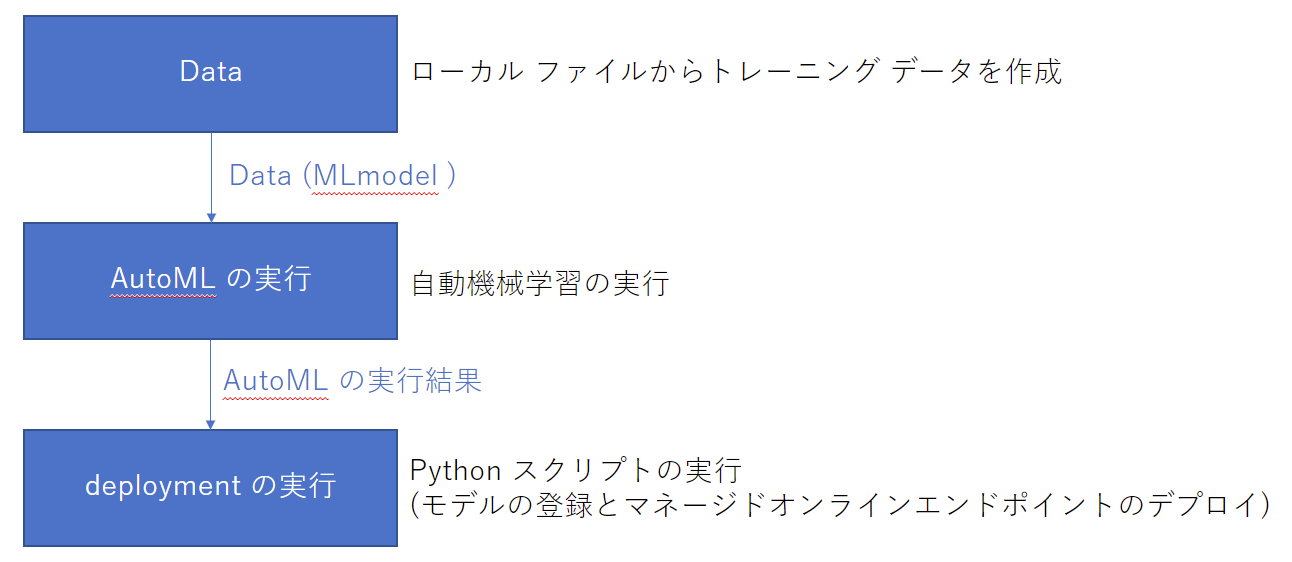
ノートブックの実行
sample-pipeline-sdkv2.zip の解凍後、aml-pipeline-sample-sdkv2.ipynb を選択し [カーネルを再起動し、すべてのセルを実行する] をクリックします。実行時には cpu-cluster という名前の STANDARD_DS3_V2 のコンピューティング クラスターが作成されます。既に存在する場合はそのコンピューティング クラスターを使用します。また、AutoML によって生成されたモデルをデプロイしたマネージド オンライン エンドポイントが作成されます。
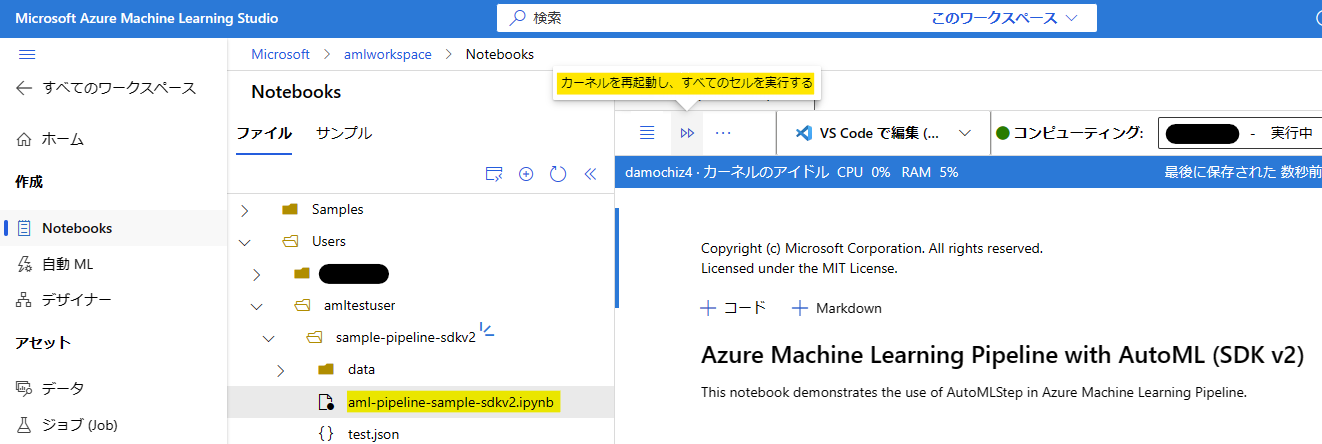
パイプラインの公開
実行が終了すると、以下の通りエンドポイントとパイプラインが作成されるため、正常に実行が終了していることを確認して [公開] ボタンをクリックし、任意の名前で実行します。実行後、パイプライン エンドポイントが作成されます。(サンプル では automl_regression_and_deployment という名前になります。)
// ノートブックで定義したパイプラインの実行結果 (この画面で [公開] ボタンを押す)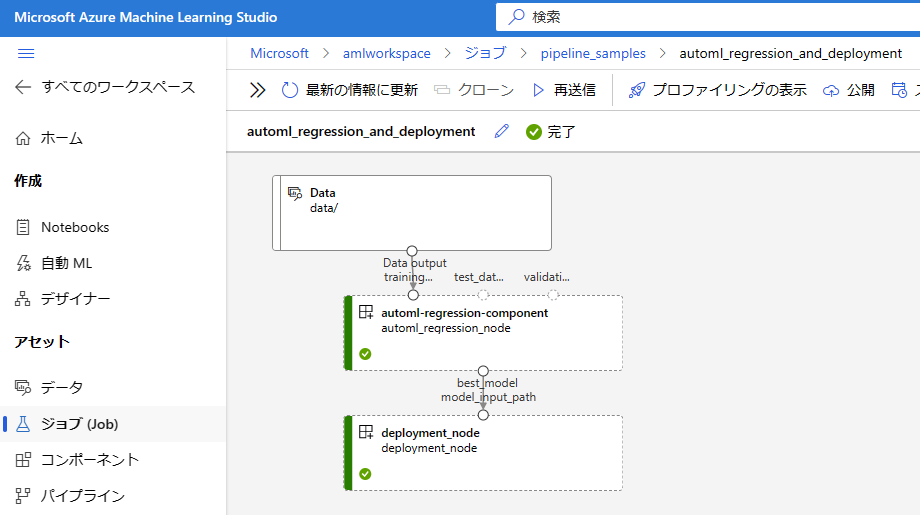
// 外部から呼び出せるように公開されたパイプラインのエンドポイント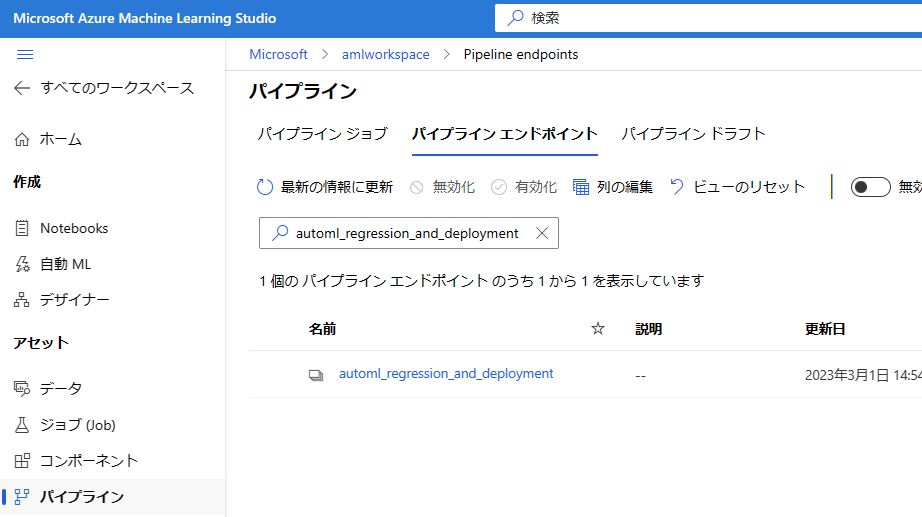
// 自動機械学習によって作成されたモデルをデプロイしたリアルタイム エンドポイント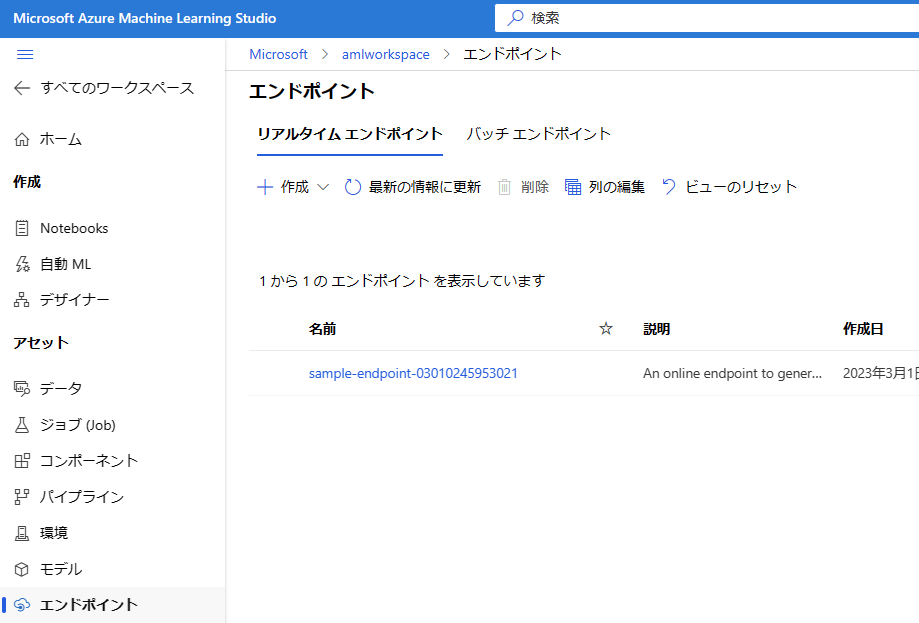
パイプラインの使用
※ 現在作成中となります。
変更履歴2023/02/28 created by Narita2023/03/01 modified by Mochizuki
※ 本記事は 「jpmlblog について」 の留意事項に準じます。
※ 併せて 「ホームページ」 および 「記事一覧」 もご参照いただければ幸いです。