本記事では、Azure Machne Learning で作成したモデルを SDK を使用して推論実行する方法を紹介します。
試験的に作成したモデルの評価を行う場合には、都度 Web サービスにデプロイする方法は効率的ではないため、ローカルにロードして推論実行する手順を紹介します。また、Web サービスにデプロイして推論を実行する方法についても併せて紹介します。
ローカルにモデルをロードして評価を行う場合
実験によって作成されたモデルのテストを行う場合、ローカル環境にロードして実行する方法をお勧めいたします。以下に、自動機械学習のチュートリアルの実行によって作成されたモデルを例にご紹介いたします。
自動機械学習では、複数のアルゴリズムと前処理の組み合わせを試し、それぞれの実行でモデルを作成します。上記チュートリアルのとおりに実行すると、「my-1st-automl-experiment」 という名前の実験の中で、複数のモデルが作成されます。このうちひとつのモデルをローカルにロードして、推論実行する方法を紹介します。
モデルは、VotingEnsemble を選択します。
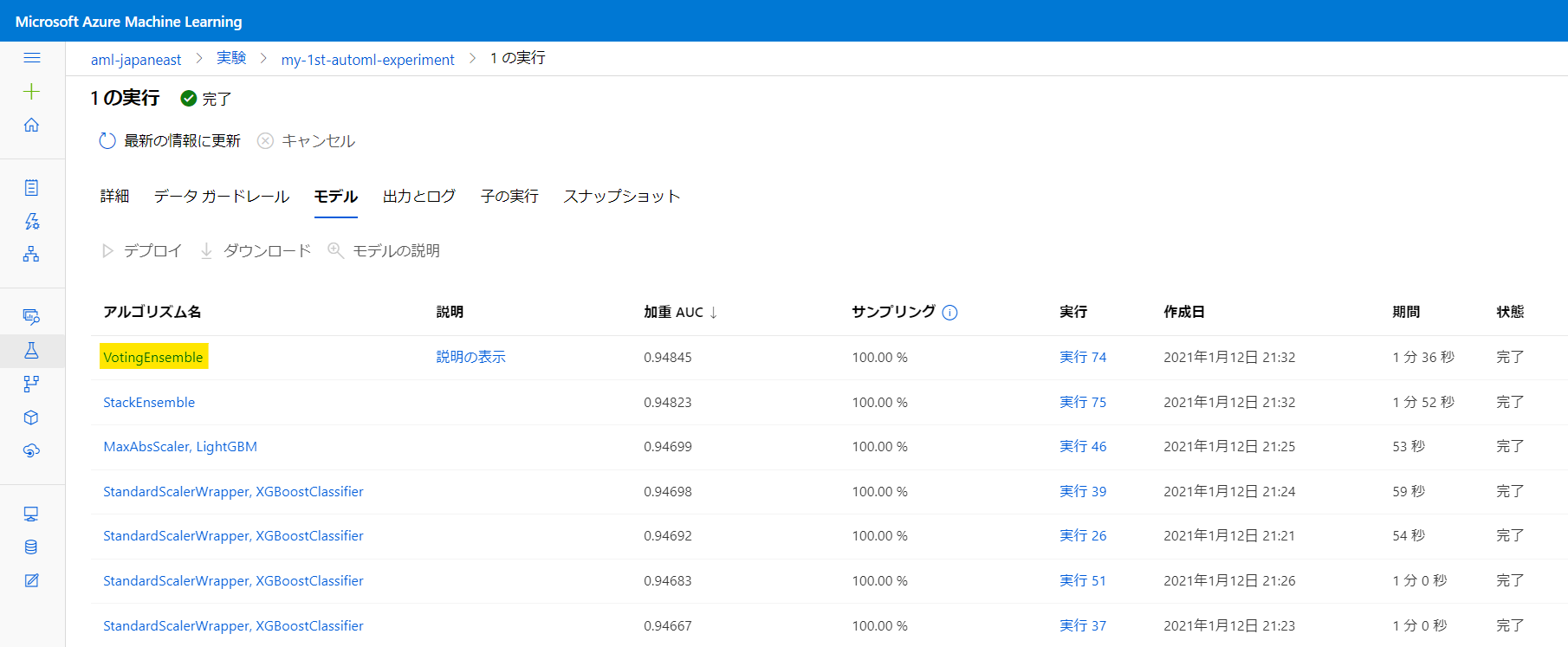
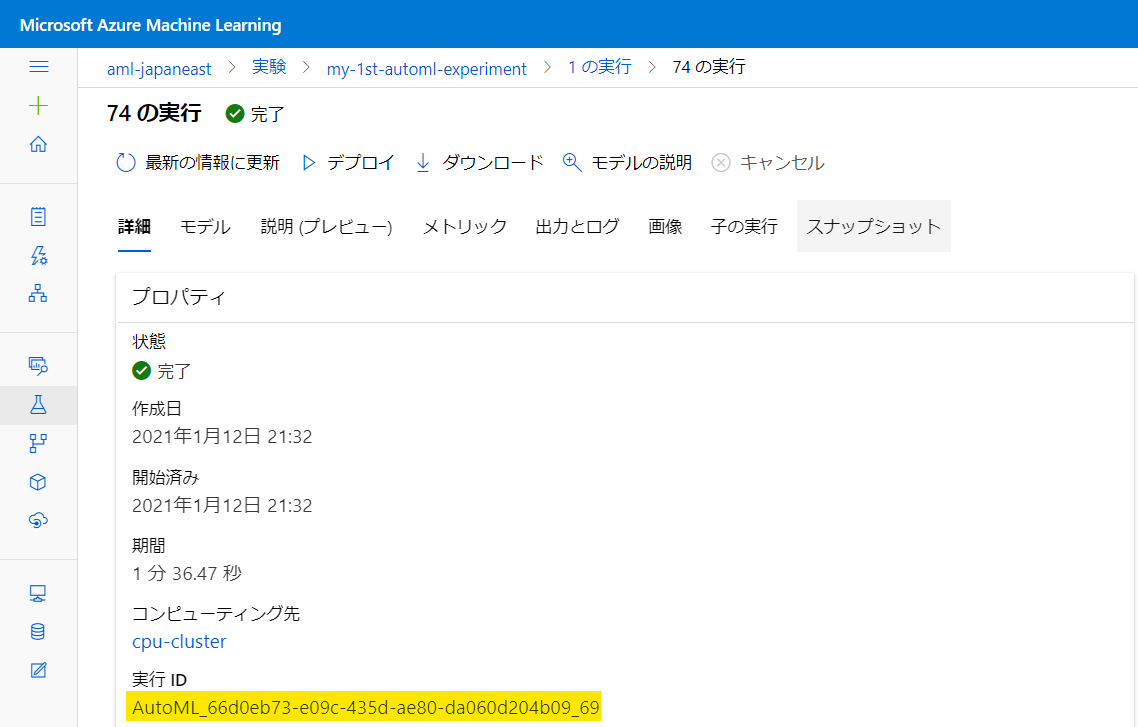
「詳細」 タブより実行 ID を確認します。
Notebooks メニューより任意のフォルダーに新しいノートブックを作成し、以下のコードを入力、実行します。experiment_name や run_id は、ご利用環境に合わせて適宜変更ください。
1 | # 実行 ID より Run オブジェクトを作成します。 |
1 | # ダウンロードしたモデルをローカルにロードします。 |
推論のテストに使用するデータは、トレーニング データに含まれていないものをご用意頂く必要があります。今回は既に用意されているテスト データを使用しますが、一般的にはトレーニング用に収集したデータの 1 割程度をテスト用に分割しておくことをお勧めします。
1 | # チュートリアルのテスト用データをデータセットとして読み込みます。 |
既存のデータセットを使用する場合、上記コード セルを以下に変更します。
2
3
4
5
>from azureml.core.dataset import Dataset
># detaset_name をデータセット名に置き換えて実行します。
>test_dataset = Dataset.get_by_name(workspace, >name='bankmarketing_test')
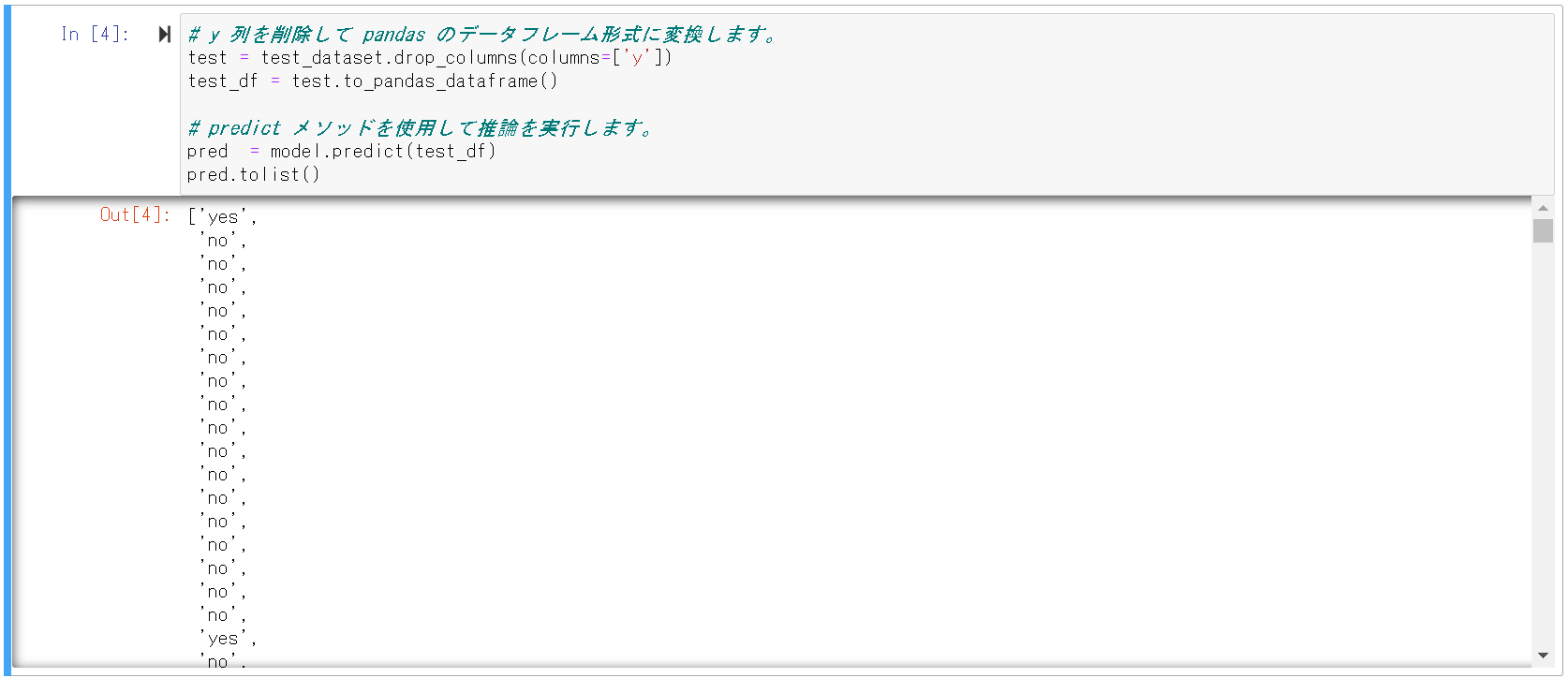
1 | # y 列を削除して pandas のデータフレーム形式に変換します。 |
以下の通り推論結果を表示できたかと思います。
これらのコードは下記サンプル ノートブック auto-ml-classification-bank-marketing-all-features.ipynb を参考にしておりますので、併せて参照ください。
注意点
時系列予測モデルの ForecastingParameters として target_rolling_window_size パラメーターを指定していると、predict の実行が失敗することが確認できています。これは predict メソッドが target_rolling_window_size パラメーターを使用したモデルでの実行をサポートしていないためです。このような場合、以下サンプル ノートブック auto-ml-forecasting-orange-juice-sales.ipynb 、にありますとおり、predict メソッドではなく forecast メソッドの利用をご検討ください。

Web サービスとしてデプロイされたモデルを使用する
作成したモデルをローカル、ACI、AKS のいずれかに Web サービスとしてデプロイした場合、要求データを REST エンドポイントに対して送信することで推論結果を得られます。
モデルのデプロイ方法は下記公開情報に纏められています。
デプロイした Web サービスの呼び出し方は、下記公開情報が参考になります。
デプロイ先がローカル、ACI、AKS それぞれのドキュメントおよびサンプル ノートブックを紹介します。
ローカル
- docs: Azure Machine Learning コンピューティング インスタンスへのモデルのデプロイ
- sample: Register model and deploy locally with advanced usages
ACI (Azure Container Instance)
- docs: Azure Container Instances にモデルをデプロイする
- sample: Register model and deploy as webservice in ACI
- sample: Deploy Multiple Models as Webservice
AKS (Azure Kubernetes Service)
- docs: Azure Kubernetes Service クラスターにモデルをデプロイする
- sample: Deploying a web service to Azure Kubernetes Service (AKS)
- sample: Deploying a web service to Azure Kubernetes Service (AKS) + SSL
- sample: Deploying a web service to Azure Kubernetes Service (AKS) + GPU
そのほか参考となる情報
Web サービスの入力データについて
Web サービスを呼び出す Json データは、{“data”: [[ 数値,数値, … ], [ 数値,数値, … ]]} という形式である必要があります。または、辞書形式で {“data”: [{ “列名”:数値, “列名”:数値, … }, { “列名”:数値, “列名”:数値, … }]} としても推論を実行可能です。
以下に、csv ファイルを入力データに変更する方法を紹介させていただきます。まず、下記のコードで推論用データ predictdata.csv を作成します。事前に作成されたデータを使用しても問題ありません。
1 | %%writefile predictdata.csv |
下記コードにて、入力用のデータへ変換します。
1 | import csv |
このとき、input_data 以下の通りです。
1 | '{"data": [[{"Name": "test1", "age": "15", "job": "none", "hobby": "car", "deposit": "150000"}, {"Name": "test2", "age": "28", "job": "office worker", "hobby": "200000", "deposit": null}, {"Name": "test3", "age": "35", "job": "bank", "hobby": "fishing", "deposit": "3600000"}, {"Name": "test4", "age": "40", "job": "journalist", "hobby": "1520000", "deposit": null}]]}' |
デザイナーで作成したモデルのデプロイ
デザイナーでは作成したパイプラインを公開するだけではなく、作成したモデルをデプロイする方法がございます。以下公開情報に纏められておりますので、参考にご参照ください。
変更履歴2021/01/13 created by Mochizuki2021/01/21 created by Mochizuki
※ 本記事は 「jpmlblog について」 の留意事項に準じます。
※ 併せて 「ホームページ」 および 「記事一覧」 もご参照いただければ幸いです。